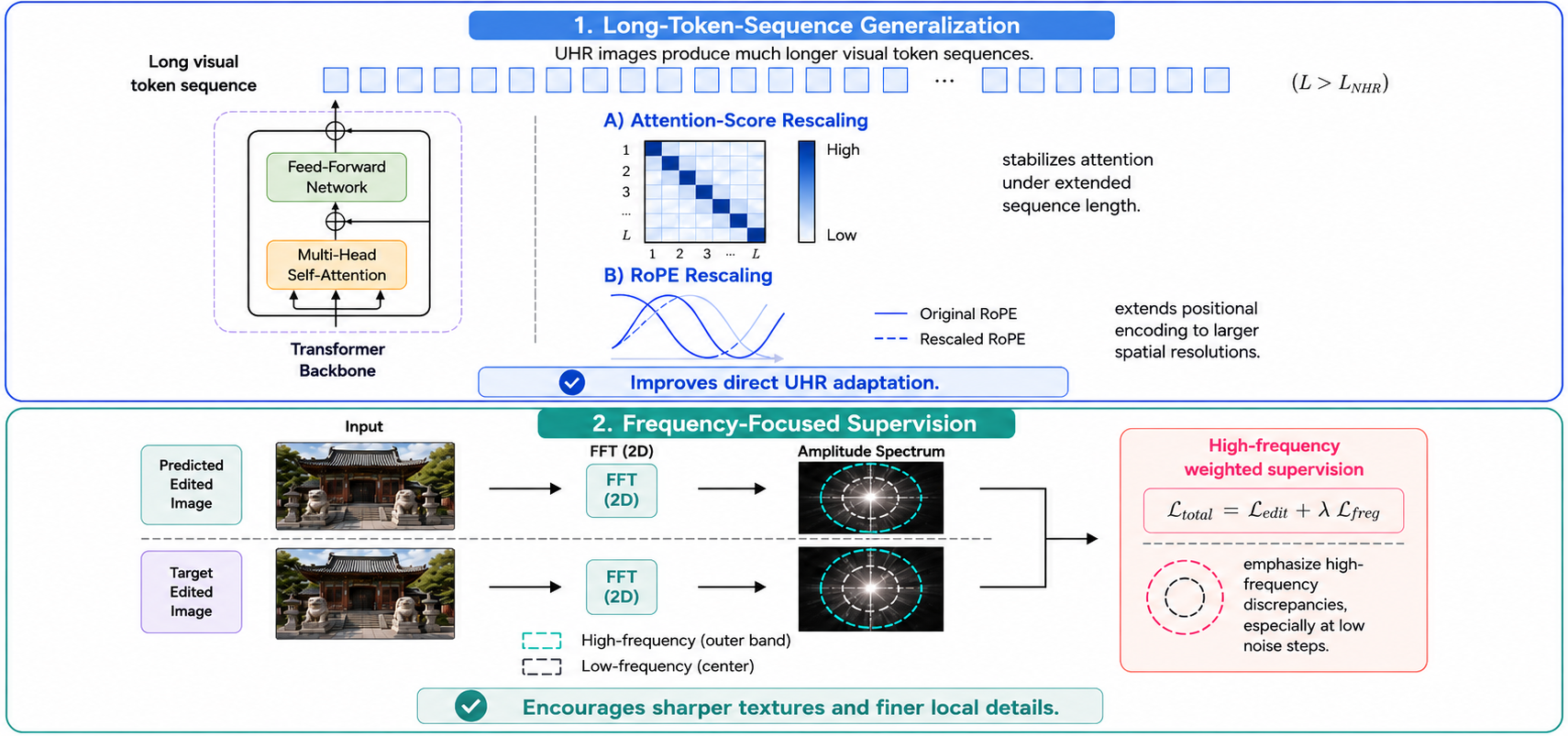
Attention Rescaling
UHR images produce much longer token sequences, which can over-smooth attention. A resolution-aware temperature sharpens attention responses back toward the pretrained regime.
CVPR 2026
The first large-scale 4K instruction-based image editing dataset, paired with a high-frequency-aware post-adaptation strategy for native UHR editing.
1Nanjing University, China 2vivo, China *Equal contribution †Corresponding author

Directly editing ultra-high-resolution images is valuable but still underexplored, mainly because high-quality 4K editing data is scarce and high-frequency texture modeling is difficult. VINS-120K introduces 120K carefully curated triplets of instruction, input image, and edited image. Each image exceeds 4K resolution, with an average size of 4656 × 4138. Built on this dataset, the paper proposes a high-frequency-aware post-adaptation strategy that extends pretrained non-high-resolution editors to the UHR regime, and evaluates them on VINS-4KEval, a 509-sample 4K benchmark covering 13 edit types.
VINS-120K is built from real-world 8K-UHD videos and carefully filtered open-source editing data, preserving native detail while expanding long-tail edit coverage.


The method adapts pretrained NHR editors to 4K by stabilizing very long token sequences and explicitly supervising high-frequency detail.
UHR images produce much longer token sequences, which can over-smooth attention. A resolution-aware temperature sharpens attention responses back toward the pretrained regime.
The rotary base is stretched using an NTK-aware principle, keeping unseen UHR positions within a more stable positional encoding range.
A dynamic 2D-DFT loss emphasizes high-frequency bands during later denoising steps, where fine texture and local details are decoded.
On VINS-4KEval, post-adapting FLUX.1-Kontext-dev improves UHR detail fidelity while preserving competitive instruction-following behavior.
The post-adapted model better preserves and synthesizes fine textures that are usually weakened by downsample-edit-upsample pipelines.
On VINS-4KEval, the adapted editor improves edit quality and detail preservation while keeping instruction adherence close to the strongest baselines.
The full table reports the best pFID among evaluated systems, with the qualitative results showing clearer high-frequency reconstruction.

| Method | Instr. Adh. | Edit Qual. | Detail Pres. | SC | PQ | VIEScore | pFID |
|---|---|---|---|---|---|---|---|
| Seedream 4.0 | 4.60 | 4.79 | 4.70 | 7.95 | 8.12 | 8.03 | 12.82 |
| AnyEdit | 3.24 | 3.89 | 3.57 | 4.09 | 7.32 | 5.71 | 18.44 |
| ICEdit | 3.76 | 4.42 | 4.09 | 5.77 | 7.81 | 6.79 | 16.69 |
| Bagel | 4.15 | 4.39 | 4.27 | 7.23 | 7.76 | 7.49 | 15.41 |
| Omnigen2 | 4.14 | 4.54 | 4.34 | 6.73 | 7.86 | 7.29 | 18.73 |
| Step1X-Edit | 4.06 | 4.50 | 4.28 | 6.94 | 7.79 | 7.37 | 15.37 |
| Kontext-dev | 4.22 | 4.60 | 4.41 | 6.95 | 7.92 | 7.43 | 12.66 |
| Kontext-dev + Post-Adaptation | 4.23 | 4.70 | 4.47 | 6.89 | 7.98 | 7.44 | 9.15 |
The same adaptation idea also transfers to Qwen-Image-Edit-2511, improving local object replacement and global scene transformation while preserving UHR visual details.

Input-output pairs from the dataset and qualitative evaluations, organized as paired scrolling cards for direct before/after comparison.
 Input
Input Output
Output Input
Input Output
Output Input
Input Output
Output Input
Input Output
Output Input
Input Output
Output Input
Input Output
Output Input
Input Output
Output Input
Input Output
Output Input
Input Output
Output Input
Input Output
Output Input
Input Output
Output Input
Input Output
Output Input
Input Output
Output Input
Input Output
Output Input
Input Output
Output Input
Input Output
Output Input
Input Output
Output Input
Input Output
Output Input
Input Output
Output Input
Input Output
Output Input
Input Output
Output Input
Input Output
Output Input
Input Output
Output Input
Input Output
Output Input
Input Output
OutputIf you find this work useful, please cite it.
@inproceedings{chen2026vins120k,
title = {VINS-120K: Ultra High-Resolution Image Editing with A Large-Scale Dataset},
author = {Chen, Zhizhou and Guan, Shanyan and Gao, Zhanxin and Ci, En and
Ge, Yanhao and Li, Wei and Zhang, Zhenyu and Yang, Jian and Tai, Ying},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year = {2026}
}Instruction